
On March 28th, Cerebras released on HuggingFace a new Open Source model trained on The Pile dataset called "Cerebras-GPT" with GPT-3-like performance. ( Link to press release)
What makes Cerebras interesting?
While Cerebras isn't as capable of a model for performing tasks when compared directly to models like LLaMA, ChatGPT, or GPT-4, it has one important quality that sets it apart: It's been released under the Apache 2.0 licence, a fully permissive Open Source license, and the weights are available for anybody to download and try out.
This is different from other models like LLaMA that, while their weights are freely available, their license restricts LLaMAs usage to only "Non-Commercial" use cases like academic research or personal tinkering.
That means if you'd like to check out LLaMA you'll have to get access to a powerful GPU to run it or use a volunteer-run service like KoboldAI. You can't just go to a website like you can with ChatGPT and expect to start feeding it prompts. (At least without running the risk of Meta sending you a DMCA takedown request.)
Proof-of-Concept to demonstrate Cerebras Training Hardware
The real reason that this model is being released is showcase the crazy silicon that Cerebras has been spending years building.
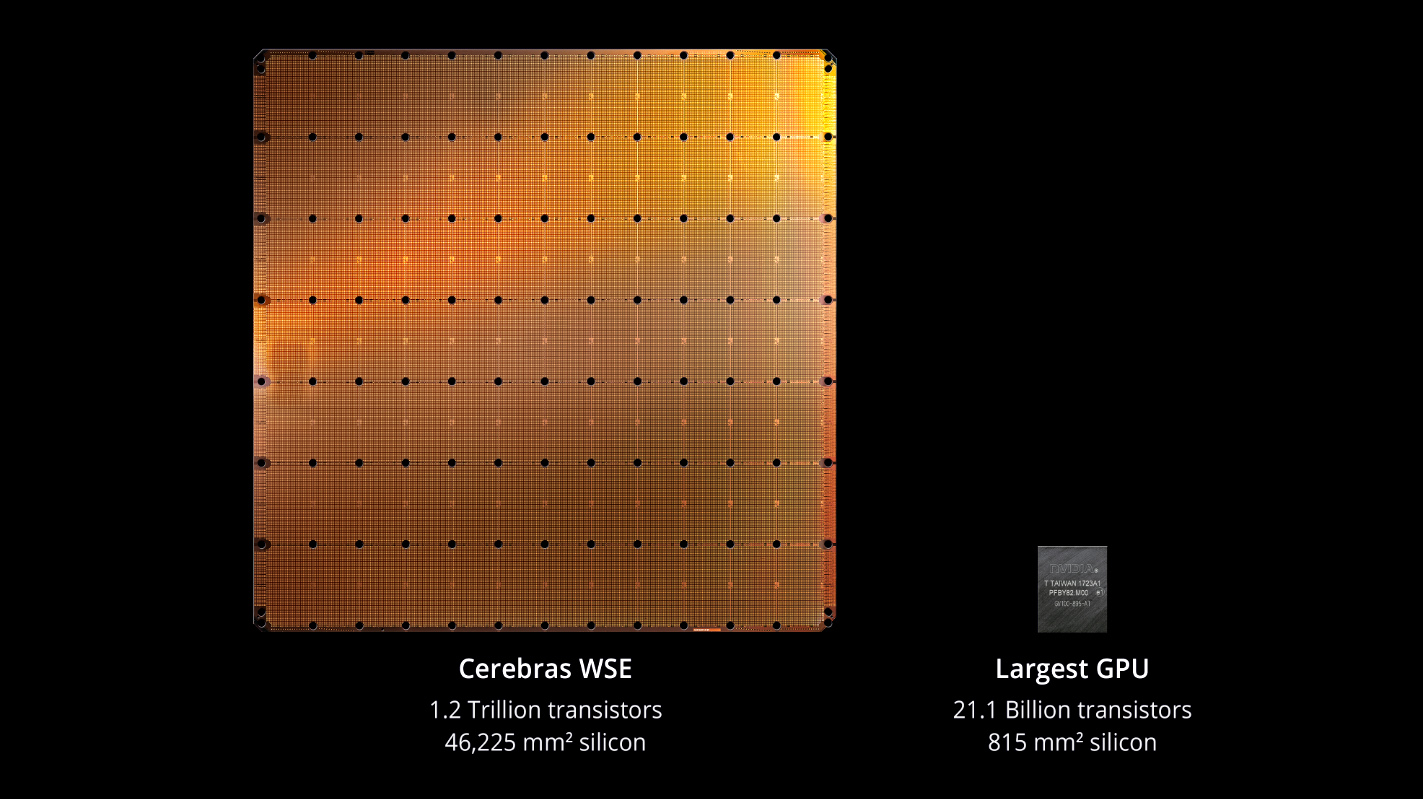
These new chips are impressive because they use a silicon architecture that hasn't been deployed in production for AI training before: Instead of networking together a bunch of computers that each have a handful of NVIDIA GPUs, Cerebras has instead "networked" together the chips at the die-level.
By releasing Cerebras-GPT and showing that the results are comparable to existing OSS models, Cerebras is able to "prove" that their product is competitive with what NVIDIA and AMD have on the market today. (And healthy competition benefits all of us!)
Cerebras vs LLaMA vs ChatGPT vs GPT-J vs NeoX
To put it in simple terms: Cerebras isn't as advanced as either LLaMA or ChatGPT (gpt-3.5-turbo). It's a
much smaller model at 13B parameters and it's been intentionally "undertrained" relative to the other models.
Cerebras is ~6% of the size of GPT-3 and ~25% of the size of LLaMA's full-size, 60B parameter model, and they
intentionally limited how long the model was trained in order to reach a "training compute optimal" state.
That doesn't mean that it's useless though. As you'll see from the data released in the Cerebras paper, this model is still a welcome addition to the available Open Source models like GPT-2 (1.5B), GPT-J (6B), and GPT NeoX (20B). It's also possible that the model can improve with additional tweaking by the community (like fine-tuning or creating LORAs for it.)
It's also just valuable for anybody building around AI that can't depend on OpenAI's monopoly for what they're building (enterprises with strict security requirements, foreign governments, or just people that want to have control over their infrastructure).
Benchmark Comparison
| Model | Params | Hella-Swag | PIQA | Wino-Grande | Lambada | ARC-e | ARC-c | OpenBookQA | BoolQ | SIQA |
|---|---|---|---|---|---|---|---|---|---|---|
| Cerebras-GPT | 13B | 51.3 | 76.6 | 64.6 | 69.6 | 71.4 | 36.7 | 28.6 | - | - |
| GPT-3 (175B) | 175B | 78.9 | 81.0 | 70.2 | 75.0 | 68.8 | 51.4 | 57.6 | 60.5 | 81.0 |
| GPT-4 (?B) | ? | 95.3 | - | 87.3 | - | - | 96.3 | - | - | - |
| LLaMA (7B) | 7B | 76.1 | 79.8 | 70.1 | - | 72.8 | 47.6 | 57.2 | 76.5 | 48.9 |
| LLaMA (13B) | 13B | 79.2 | 80.1 | 73.0 | - | 74.8 | 52.7 | 56.4 | 78.1 | 50.4 |
| LLaMA (33B) | 33B | 82.8 | 82.3 | 76.0 | - | 80.0 | 57.8 | 58.6 | 83.1 | 50.4 |
| LLaMA (65B) | 65B | 84.2 | 82.8 | 77.0 | - | 78.9 | 56.0 | 60.2 | 85.3 | 52.3 |
| GPT-J (6B) | 6B | 66.1 | 76.5 | 65.3 | 69.7 | - | - | - | - | - |
| GPT-NeoX-20B | 20B | - | 77.9 | ~67.0 | 72.0 | ~72.0 | ~39.0 | ~31.0 | - | - |
It's a bit difficult to compare apples-to-apples between all of these different models, but I did my best to squeeze the data together in a way that made it easier to understand.
As you can see from looking at this table: Cerebras-GPT is roughly the same as GPT-J and GPT NeoX, and sometimes even worse, for tasks like OpenBookQA and ARC-c ("complex"). From looking at what these tests actually involve, it seems that both of those tasks rely on some amount of "common sense" knowledge to get right (determing the correct answer requires using knowledge that isn't included in the question anywhere).

...and then there is GPT-4 crushing everything else in this table!
Is Cerebras-GPT worth using?
Based on the data above it's not really better than any existing OSS models so it's hard to say if it's a better choice than GPT-J, GPT NeoX, or other AI models for any tasks. Perhaps with some fine-tuning the model may be able to perform better than either of those, but I'll let somebody more qualified than me answer that question instead!
Want to learn more?
Come join our Discord and share your thoughts with us. We've been building a community of AI hackers to help keep up with the insane pace of development happening right now in the AI world, and we'd love to have you join us!
Updates
2022-03-29 @ 2pm PST: Fixed some typos and rephrased some text.
